탐색적데이터분석(EDA) 방법을 알아보겠습니다. 데이터 분석을 위해 가장 먼저 필요한 것은 데이터입니다. 데이터는 데이터 수집 활동을 통해 모으게 됩니다.

데이터 분석의 첫걸음 : 데이터 수집 --> 데이터 눈으로 쭉 확인하기
데이터는 항상 정제된 상태로 있지는 않습니다. 중간에 비어있는 데이터도 있고, 금액이 들어가야 할 곳에 문자가 들어있거나 날짜가 들어가 있기도 합니다. 이런 데이터의 번잡스러움을 처리하기 위해 데이터 정제 작업을 해야 합니다.
1. 탐색적데이터분석(EDA) 란
EDA(Exploratory Data Analysis)란 기존의 통계적 가설 검정과 같은 통계분석을 위한 데이터 분석이 아닌, 가설 설정이나 명확한 목적 없이 데이터 자체에 숨겨진 의미, 인지하지 못했던 가치를 파악하기 위해 탐색적으로 데이터를 분석하는 과정을 말합니다.
EDA는 벨연구소의 수학자인 존 튜키가 만든 프로세스로 확증적 데이터 분석과는 대조적인 데이터 분석 프로세스로 개발 된 내용입니다.
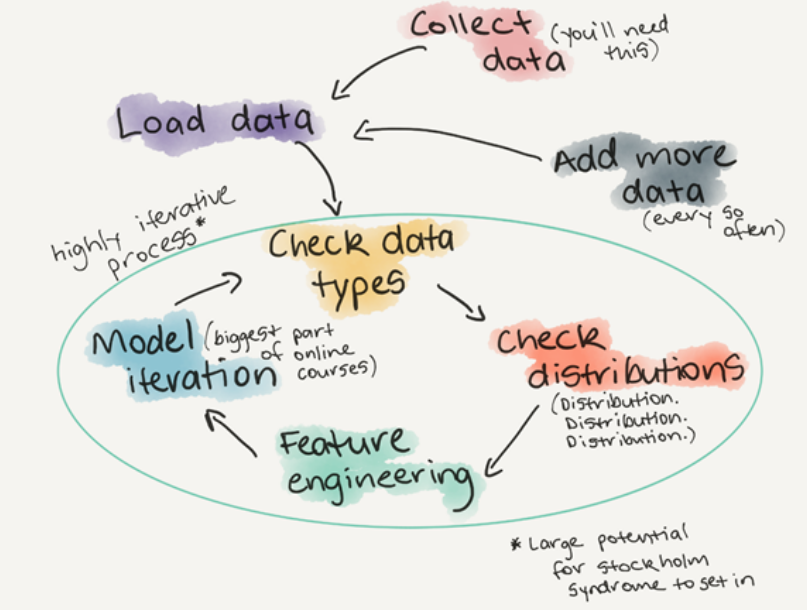
EDA는
"데이터수집 --> 데이터 적재 --> 반복 (데이터타입 점검 --> 데이터 분산 점검 --> 피처 엔지니어링 --> 모델 반복 -->)"
의 프로세스 입니다.
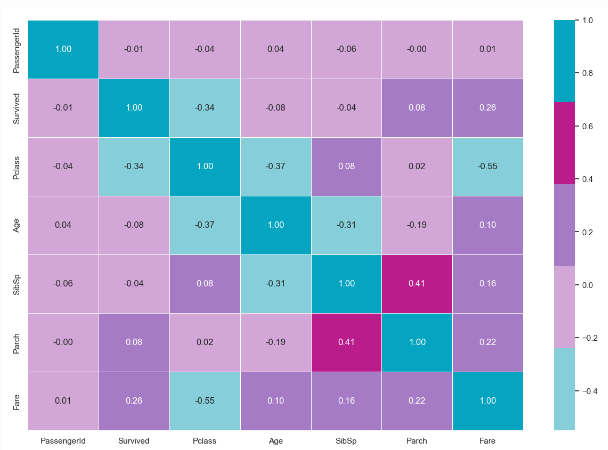
매트릭스 그래프를 통해서 변수간 관련도를 파악합니다.
2. 데이터 정제(Data Cleanzing)
데이터를 수집하면 제일 먼저 할 일은 데이터를 쭉 확인하는 작업입니다. 자세하게 보는 것이 아닌, 위 아래, 좌 우로 데이터를 눈으로 확인하는 작업입니다.
눈의 정확성은 떨어지지만 개인의 경험은 그 데이터에서 이상한 부분을 찾아냅니다. 만일 찾지 못하더라도 걱정할 필요는 없습니다. 빠진 데이터나 이상한 데이터를 찾는 방법이 제공되고 있기 때문입니다.
하지만, 이 프로그램 방법이 모든 것을 해결해 주지는 못합니다. 그래서 눈으로 검토하는 작업과 프로그램으로 처리하는 방법이 공존해야 합니다.
정제 대상이 되는 데이터는 2가지로 분류할 수 있습니다. 하나는 데이터가 없는 결측치와 또하나는 이상한 값으로 볼 수 있는 이상치입니다.
- 결측치(Missing Value) : 데이터 수집 과정에서 측정되지 않거나 누락된 데이터
- 이상치(Outlier) : 보통 관측된 데이터의 범위에서 많이 벗어난 아주 작은 값이나 큰 값
3. 결측치(Missing Value) 확인 및 처리
1) 결측치를 확인하는 방법
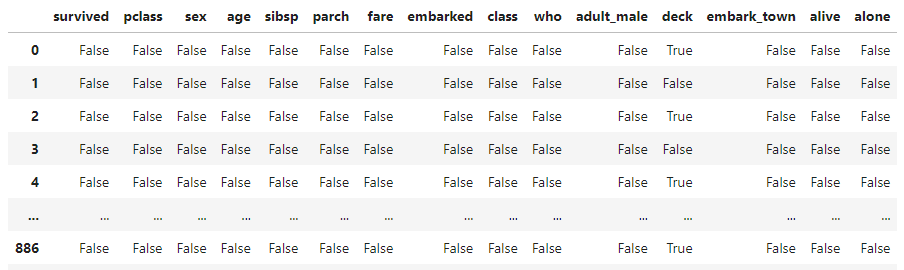
결측치를 확인하는 방법은 파이썬에서 isnull(), isna() 함수를 사용합니다. 결과는 True, False의 Boolean으로 떨어집니다. 데이터 셀 하나하나에 대해서 True, False를 보여주기 때문에 한눈에 확인하기 어렵습니다.
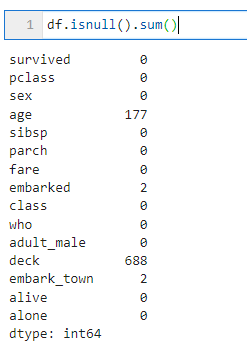
이럴 때 isnull().sum() 함수를 사용합니다. 그러면 결과는 각 칼럼에 대해 null이 몇 개인지를 나타내 줍니다. 값이 0보다 큰 칼럼에 결측치가 있는 것이죠.
import pandas as pd
import numpy as np
import seaborn as sns
df = sns.load_dataset('titanic')
df.isnull()
- 칼럼별 null 갯수 확인
df.isnull().sum()
2) 결측치를 처리하는 방법
결측치를 처리하는 가장 쉬운 방법은 삭제입니다. 하지만 삭제는 많은 데이터 손실을 가져오게 됩니다. 그래서 다른 값으로 대체하는 방식을 취합니다. 결측치가 있는 칼럼이 나이, 수량, 금액 등 수치데이터인 경우와 '남자, 여자'와 같은 카테고리 형태의 데이터인 경우에 처리하는 방식이 다릅니다.
수치데이터의 결측치 처리
- 평균값으로 대체: 결측이 아닌 데이터 값의 평균을 계산해서 반영
- 최솟값으로 대체: 결측이 아닌 데이터 값에서 최솟값을 반영
- 최댓값으로 대체: 결측이 아닌 데이터 값에서 최댓값을 반영
- 중앙값으로 대체: 결측이 아닌 데이터 값에서 중앙값을 반영
- 최빈값으로 대체: 결측이 아닌 데이터 값에서 가장 빈도가 높은 최빈값을 반영
- 임의값으로 대체: 결측치에 임의의 값을 지정하여 반영 (예. 나이 경우 '30')
- 결측 데이터가 있는 인덱스 확인하기
# ----- null Data 위치 확인하기
df.loc[df['age'].isnull(), 'age']
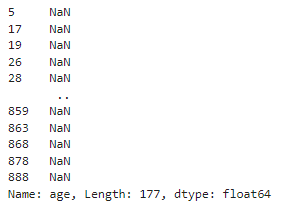
- 평균, 최대, 최소, 중앙값 확인
print('mean : ', df['age'].mean())
print('max : ', df['age'].max())
print('min : ', df['age'].min())
print('median: ', df['age'].median())
print('mode : ', df['age'].mode()[0]) -- 최빈값
# --- Output -----
mean : 29.69911764705882
max : 80.0
min : 0.42
median: 28.0
mode : 24.0
- 결측값에 max 값 반영하기
df['age'].fillna( df['age'].max()).head(7)
# ----- Output -----
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
5 80.0 <-- max값이 반영됨
6 54.0
Name: age, dtype: float64
카테고리 데이터의 결측치 처리
- 최빈값 반영: 가장 많이 나타나는 최빈값을 반영
- 임의값 반영: 지정한 데이터를 반영
임의값을 지정할 때는 관련된 업무 및 사업 성격에 맞추어 지정해 주어야 합니다. 학생 데이터를 다루는 데에 기업에서 다루는 데이터의 임의값을 반영하면 안 되겠죠.
임의값 설정은 무턱대고 하기보다, 탐색적데이터분석을 진행하면서 결정할 수 있습니다. 전반적인 데이터 검토를 하다 보면 유의미한 수치나 카테고리가 나타나게 됩니다.
임의값 지정 예시
- 나이 결측값은 '30'세로 한다.
- 성별 결측값은 '남자'로 한다.
- 도시 결측값은 '서울'로 한다.
3) 하나 더 생각해 보기
결측값에 반영할 대체값을 전체 데이터보다는 범주를 좁혀서(디테일하게 하여) 계산하면 더 정밀한 결과를 반영할 수 있습니다. 예를 들어, 대한민국 전체 데이터 보다는 서울 지역 데이터만 , 더 좁히면 강남구의 데이터만을 대상으로 하는 방식입니다.
일반적인 수치를 반영해야 하는 경우도 있지만, 더 전문적인 수치를 반영해야 하는 경우도 있습니다. 데이터 분석 작업을 하면서 어떤 것이 더 유효한지 검토와 협의의 시간을 가지시기 바랍니다.
이렇게 데이터 분석에서의 결측치 관련해서 알아봤습니다. 결측치를 확인하는 방법과 대체하는 방법입니다. 업무에 참조하시기 바랍니다.
'IT' 카테고리의 다른 글
| 파이썬 아나콘다(Anaconda) 삭제- 삭제 후 리부팅, 설치 위치, Uninstall Anaconda (0) | 2023.11.15 |
|---|---|
| [데이터 1일 1로그] 데이터 조작하기 - SQL, 쿼리, Select,Update, Delete, Insert (0) | 2023.11.11 |
| [데이터 1일 1 로그] 데이터의 단위 - 비트, 바이트, 더블바이트, 문자 (0) | 2023.11.10 |
| 귀도 반 로섬, 파이썬을 만든 사람, 파이썬을 왜 만들었나 (0) | 2023.11.09 |
| 매치업(MatchUp) 공기업, 교육기관, 학습자와 함께 직무역량 향상 과정-확인해보세요 (0) | 2023.11.03 |



